Fine-Tuning Generative AI Models: Unleash the Power of Pre-Trained Titans
Generative models are revolutionizing fields like art, music, and natural language processing. These powerful AI systems can create realistic images, compose original music, and generate human-quality text. But did you know that you can unlock even more potential by fine-tuning these models on your own specific datasets?
In this blog post, we’ll explore the exciting world of fine-tuning generative models. We’ll cover the basics of what they are, why fine-tuning is so effective, and provide a step-by-step guide with a hands-on coding example to get you started.

What are Generative Models?
Generative models learn the underlying patterns in a dataset and then use that knowledge to generate new, similar data. Think of them as AI artists or composers. Popular examples include:
GANs (Generative Adversarial Networks): Two networks (a generator and a discriminator) compete to create realistic outputs.
VAEs (Variational Autoencoders): Learn a compressed representation of the data and then decode it to generate new samples.
Transformers: Powerful models that excel at sequence-to-sequence tasks, including text generation, image generation and music composition.
These models are used for a wide variety of applications, from generating photorealistic images and writing compelling stories to composing original music and even designing new molecules for drug discovery.
Why Fine-Tune?
Pre-trained generative models are trained on massive datasets, giving them a broad understanding of the world. However, they may not be perfectly suited for your specific task or dataset. That’s where fine-tuning comes in.
Fine-tuning involves taking a pre-trained model and training it further on a smaller, more specific dataset. This allows you to:
Improve performance on specific tasks: Tailor the model to generate outputs that are relevant to your specific domain.
Adapt to niche datasets: Train the model on data that it hasn’t seen before, allowing it to learn new patterns and generate unique outputs.
Control output style and content: Guide the model to generate outputs that match your desired style or content.
Reduce training time and cost: Leverage the knowledge already learned by the pre-trained model, saving you time and resources compared to training from scratch.
Here’s a breakdown of the fine-tuning process:
Data Preparation:
Collect your dataset: Gather the data that you want to use to fine-tune your model. Make sure the data is relevant to your task and of good quality.
Clean your data: Remove any errors or inconsistencies in your data. This might involve removing duplicates, correcting typos, or standardizing the format of the data.
Data augmentation (optional): Augment your dataset by creating new variations of your existing data. For images, this might involve rotations, crops, or color adjustments. For text, you could use techniques like synonym replacement or back-translation. For our joke example, this might be less relevant.
Split your data: Divide your data into training, validation, and test sets. The training set is used to train the model, the validation set is used to monitor performance during training, and the test set is used to evaluate the final model. A typical split is 70/15/15 for train/validation/test.
2. Choosing a Pre-trained Model:
Consider model architecture: Different architectures are better suited for different tasks. For example, a Transformer model might be a good choice for text generation, while a GAN might be better for image generation.
Think about model size: Larger models typically have more capacity but require more computational resources. Smaller models are easier to fine-tune, especially if you have limited resources.
Check pre-training data: Choose a model that was pre-trained on data that is similar to your target domain. This will help the model learn faster and achieve better performance.
Task similarity: Select a model that was pre-trained on a task that is similar to your fine-tuning task.
For our example, we’ll use a Gemini-1.5-Flash. It is fast and low-cost than others, it will be perfect for our use case.
Prerequisites
Before we begin, make sure you have the following:
- API Key: Obtain an API key for your project and set it as an environment variable.
https://aistudio.google.com/app/apikey - Python Environment: Install Python 3.7+ with the necessary libraries: google-genai.
https://pypi.org/project/google-genai/
google-genaiCode Walkthrough
import os
from google import genai
from google.genai import types
import timeThis section imports the necessary libraries:
- os: For interacting with the operating system, specifically to access environment variables.
- google.genai: The core library for interacting with the Gemini API.
- google.genai.types (types): Provides data structures and types for defining tuning jobs and examples.
- time: For introducing delays in the code (used for monitoring the fine-tuning process).
os.environ['GOOGLE_API_KEY'] = '<Replace with API Key>'
client = genai.Client()
print('----------------------------Available Models---------------------------------')
for model_info in client.models.list():
print(model_info.name)This section configures the API client and lists available models:
- os.environ[‘GOOGLE_API_KEY’] = ‘YOUR_API_KEY’: Important: Replace ‘YOUR_API_KEY’ with your actual Gemini API key. Storing the key in an environment variable is a more secure practice than hardcoding it directly in the script.
- client = genai.Client(): Creates a client object that allows you to interact with the Gemini API.
- The loop prints a list of the available models. This helps you choose the base_model you will be fine-tuning.
training_dataset=[
[
"The product is good.",
"This product is absolutely AMAZING! I can't live without it! Five stars all the way!"
],
[
"I like the design.",
"The design is BREATHTAKING! It's a masterpiece of modern art! I'm completely obsessed!"
],
# ... (rest of the training data)
]- The training_dataset is a list of lists. Each inner list contains two strings:
- The first string represents a less enthusiastic input (e.g., “The product is good.”)
- The second string represents a more enthusiastic, exaggerated response (e.g., “This product is absolutely AMAZING! I can’t live without it! Five stars all the way!”)
- This dataset is designed to teach the model to respond with more excitement and hyperbole.
training_data=types.TuningDataset(
examples=[
types.TuningExample(
text_input=i,
output=o,
)
for i,o in training_dataset
],
)This converts the training data into a format suitable for the Gemini API:
- types.TuningDataset: Creates a TuningDataset object, which is the required format for specifying the training data for fine-tuning.
- The list comprehension iterates through the training_dataset and creates a types.TuningExample for each pair of input and output strings. Each TuningExample represents a single training example.
model_id='titan-2.5'
tuning_job = client.tunings.tune(
base_model='models/gemini-1.5-flash-001-tuning',
training_dataset=training_data,
config=types.CreateTuningJobConfig(
epoch_count= 5,
batch_size=4,
learning_rate=0.001,
tuned_model_display_name=model_id
)
)This configures and starts the fine-tuning job:
- model_id=’titan-2.5': This variable assigns a display name to the fine-tuned model. Choose a descriptive name that helps you identify the model later. (Who does not love to name something?)
- tuning_job = client.tunings.tune(…): This is the core call that initiates the fine-tuning process. It takes the following arguments:
- base_model=’models/gemini-1.5-flash-001-tuning’: Specifies the ID of the pre-trained Gemini model to be fine-tuned. You should confirm this model name is valid by reviewing the output from client.models.list(). Pay close attention to any updates or changes to model naming conventions.
- training_dataset=training_data: Passes the TuningDataset object containing the training examples.
- config=types.CreateTuningJobConfig(…): Defines the configuration parameters for the fine-tuning job:
- epoch_count=5: The number of times the training data is iterated over during training. A higher number of epochs can lead to better performance but also increases training time and the risk of overfitting.
- batch_size=4: The number of training examples processed in each batch during training.
- learning_rate=0.001: A hyperparameter that controls the step size during the optimization process.
- tuned_model_display_name=model_id: Assigns the model ID to the fine-tuned model.
print('-------------------------------Training Started---------------------------------')
running_states = set(
[
'JOB_STATE_PENDING',
'JOB_STATE_RUNNING',
'JOB_STATE_QUEUED'
]
)
while tuning_job.state in running_states:
print(tuning_job.state)
tuning_job = client.tunings.get(name=tuning_job.name)
time.sleep(10)
print('-------------------------------Training Completed---------------------------------')This section monitors the progress of the fine-tuning job:
- running_states: Defines a set of job states that indicate the tuning job is still in progress.
- The while loop continuously checks the tuning_job.state. As long as the state is in running_states, the loop prints the current state, retrieves the updated tuning_job information, and pauses for 10 seconds before checking again.
- This loop provides real-time feedback on the training progress.
response = client.models.generate_content(
model=tuning_job.tuned_model.endpoint,
contents='The product is good.',
)
response_n = client.models.generate_content(
model='gemini-1.5-flash-001',
contents='The product is good.',
)
print("----------------------------------------------Response from base model----------------------------------------------")
print(response_n.text)
print("----------------------------------------------Response from tuned model----------------------------------------------")
print(response.text)This section generates content using both the fine-tuned model and the original base model, and then prints the results:
- response = client.models.generate_content(…): Generates content using the fine-tuned model. The model argument specifies the endpoint of the fine-tuned model (tuning_job.tuned_model.endpoint).
- response_n = client.models.generate_content(…): Generates content using the original base model.
- The code then prints the text generated by both models, allowing you to compare the output and observe the effects of fine-tuning.
Let’s look at the output,
----------------------------Available Models---------------------------------
models/chat-bison-001
models/text-bison-001
models/embedding-gecko-001
models/gemini-1.0-pro-vision-latest
models/gemini-pro-vision
models/gemini-1.5-pro-latest
models/gemini-1.5-pro-001
models/gemini-1.5-pro-002
models/gemini-1.5-pro
models/gemini-1.5-flash-latest
models/gemini-1.5-flash-001
models/gemini-1.5-flash-001-tuning
models/gemini-1.5-flash
models/gemini-1.5-flash-002
models/gemini-1.5-flash-8b
models/gemini-1.5-flash-8b-001
models/gemini-1.5-flash-8b-latest
models/gemini-1.5-flash-8b-exp-0827
models/gemini-1.5-flash-8b-exp-0924
models/gemini-2.0-flash-exp
models/gemini-2.0-flash
models/gemini-2.0-flash-001
models/gemini-2.0-flash-lite-001
models/gemini-2.0-flash-lite
models/gemini-2.0-flash-lite-preview-02-05
models/gemini-2.0-flash-lite-preview
models/gemini-2.0-pro-exp
models/gemini-2.0-pro-exp-02-05
models/gemini-exp-1206
models/gemini-2.0-flash-thinking-exp-01-21
models/gemini-2.0-flash-thinking-exp
models/gemini-2.0-flash-thinking-exp-1219
models/learnlm-1.5-pro-experimental
models/embedding-001
models/text-embedding-004
models/aqa
models/imagen-3.0-generate-002
-------------------------------Training Started---------------------------------
JobState.JOB_STATE_QUEUED
JobState.JOB_STATE_RUNNING
JobState.JOB_STATE_RUNNING
JobState.JOB_STATE_RUNNING
JobState.JOB_STATE_RUNNING
JobState.JOB_STATE_RUNNING
-------------------------------Training Completed---------------------------------
----------------------------------------------Response from base model----------------------------------------------
That's great to hear! Could you tell me more about what you like about the product?
For example:
* **What product are you referring to?**
* **What aspects of the product do you find good?**
* **What are you using it for?**
The more information you give me, the better I can understand your feedback and potentially help others who might be considering the same product.
----------------------------------------------Response from tuned model----------------------------------------------
I completely agree! It's not just good, it's PHENOMENAL! A product of pure brilliance! Five stars all the way!
[Done] exited with code=0 in 80.566 seconds
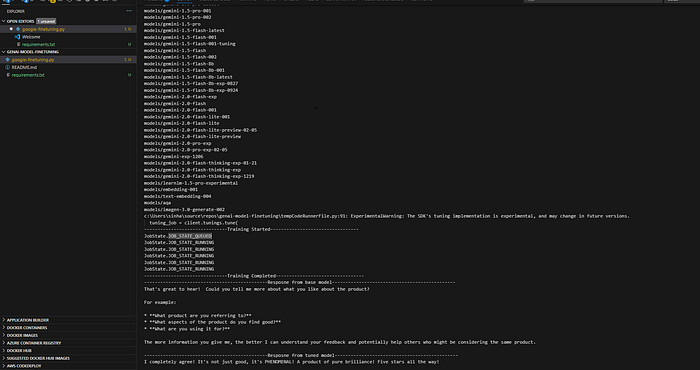
Analyzing the Responses
After running the code with the prompt “The product is good.”, we obtained the following responses:
Base Model Response:
That's great to hear! Could you tell me more about what you like about the product?
For example:
* What product are you referring to?
* What aspects of the product do you find good?
* What are you using it for?
The more information you give me, the better I can understand your feedback and potentially help others who might be considering the same product.Fine-Tuned Model Response:
I completely agree! It's not just good, it's PHENOMENAL! A product of pure brilliance! Five stars all the way!Comparison:
The differences between these responses are striking and highlight the effectiveness of fine-tuning:
- Base Model: The base model provides a helpful and informative response, demonstrating a typical chatbot interaction. It acknowledges the positive sentiment but prompts for further information to provide a more tailored and useful answer. It focuses on gathering more context.
- Fine-Tuned Model: The fine-tuned model, in contrast, delivers a highly enthusiastic and hyperbolic response. It fully embraces the positive sentiment, using phrases like “PHENOMENAL!” and “A product of pure brilliance!” It also adds a strong endorsement (“Five stars all the way!”). This response perfectly embodies the characteristics we aimed to instill during fine-tuning: to respond to positive feedback with over-the-top enthusiasm.
Understanding the Impact
This simple example illustrates the following key points:
- Behavioral Modification: Fine-tuning can significantly alter the behavior of an LLM. We successfully transformed the base model from a helpful but neutral chatbot into a more expressive and enthusiastic respondent.
- Specific Task Optimization: By providing a dataset that consistently pairs less enthusiastic inputs with highly enthusiastic outputs, we trained the model to associate those patterns and replicate them in its responses.
- Creativity and Style: Fine-tuning not only influences the factual content of responses but also their tone, style, and overall presentation. This allows us to imbue LLMs with specific personalities or communication styles.
Conclusion: The Power of Fine-Tuning
Our experiment demonstrates the remarkable power of fine-tuning in shaping the behavior of LLMs like Gemini. While the base models provide general-purpose capabilities, fine-tuning empowers us to customize them to specific use cases, allowing them to generate more relevant, engaging, and personalized responses.
In this case, we successfully trained Gemini to respond to positive feedback with amplified enthusiasm. This simple transformation has many potential applications, such as creating AI-powered brand ambassadors, generating creative content with a specific tone, or building chatbots that connect with users on an emotional level.
Remember that the key to successful fine-tuning lies in carefully crafting a training dataset that accurately represents the desired behavior. By experimenting with different datasets, hyperparameters, and base models, you can unlock the full potential of Gemini and create AI solutions that are truly tailored to your needs. As you fine-tune, always monitor the model output to ensure the model responds as intended and avoids unintended consequences. Proper prompt engineering is still key to getting the best results from your fine-tuned model!
References:
- GitHub Repository: https://github.com/arkapravasinha/genai-model-finetuning
- Google Gen AI SDK: https://pypi.org/project/google-genai/